Blog / Healthcare Data Analytics on GCP
Healthcare analytics encompasses the process of analyzing data pertaining to the healthcare industry and helps in predicting trends, improving outreach and in certain aspects control the spread of diseases. The healthcare data collected by the hospitals could be put to use by the hospitals for providing better services, improving existing procedures and offering better patient care services.
The challenges with Healthcare data:
Healthcare data is generally collected at every stage and there is no scarcity of data. However, the challenge is with data originating from disparate sources the datasets are usually complex and not compatible. The data received from a medical trial, for instance, could be very different than the one originating from the drug trial. Also, the data is not normalized from every disparate source.
The data size is another challenge as petabytes of data get collected with different systems and services. The data pipelines handling this data will also be different given the scale and the applications the pipelines support.
The rate at which the data needs to be processed and the handling of the processing steps add to the complexity of handling healthcare data.
With all the problems that need tackling like scalability, complexity, speed of decision making and the analytics capabilities needed, Google Cloud Platform can help in finding insights out of the healthcare data.
General Architecture – data foundation and warehousing in GCP
The generic architecture diagram below shows the process flows of data from the acquisition stage till it is used for visualization and running machine learning models.
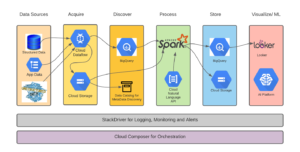
Data Sources
The data sources for healthcare data could be from application outputs, logs, data generated in transactions in hospitals, real-time data generated from the healthcare machinery, etc. All of these data sources generate data in different times and formats. Batch processing of transactional data is acceptable for the hospital data whereas the real-time data is of utmost importance for the data produced from the machinery used in critical care.
Acquire
Since data is both real-time and batch process-oriented, a pipeline has to be created that caters to both real-time and batch ingestion. Cloud DataFlow is the GCP implementation of Apache Beam that can handle both batch and real-time data flows. The transactional data from RDBMS sources can be ingested into BigQuery staging tables. The unstructured data and semi-structured data could be ingested into Cloud Storage buckets.
Discover
The data ingested into BigQuery tables and data in GCS (Google Cloud Storage) buckets can be run through ETL pipelines to clean and transform data. Data Catalog can be utilized for data discovery and metadata management.
Process
The processing engine for bringing together multiple sources of data and getting insights out of the data will be data and compute-intensive tasks. The Spark framework could be put to use as it provides parallel processing computations.
Store
The structured data that is transformed and insights derived from it will need to be stored in a data warehouse. BigQuery is a serverless application in GCP that could be queried to work with the insights derived from data. The unstructured data could be stored on Google Cloud Storage for further analysis in machine learning applications.
Visualize / Machine Learning
Data that is residing in the data warehouse could be utilized to visualize data on dashboards. Also, the data on BigQuery and Cloud Storage could be used for training models using the AI Platform on GCP.
Composer
All these defined steps need to be run in the pipeline and the same has to be orchestrated. Cloud Composer on GCP is a GCP implementation of Apache Airflow that takes care of the orchestration needs.
StackDriver
All the applications involved in the data analytics generate logs. StackDriver is a logging, monitoring, and alerting tool. It can be used to store logs, monitor the health of the systems and generate alerts wherever needed.
A customizable solution: Cloud Healthcare API
In addition to the general data analytics that could be performed as mentioned in the above architecture, GCP has custom APIs specifically handling the needs of healthcare data.
HL7 standards are the industry-accepted standards to deal with data pertaining to healthcare. The standards define a framework for the exchange, integration, sharing, and retrieval of healthcare data in electronic form. All the frameworks and versions of healthcare data such as HL, HLV2, FHIR are supported in the Cloud Healthcare API on the Google Cloud Platform. Digital Imaging and Communication in Medicine (DICOM) is another standard for transmitting, storing, retrieving, printing, processing, and displaying medical information. GCP Cloud Healthcare API supports DICOM data standards as well.
On Google Cloud Platform, the data repositories could be built on Google Cloud Storage to store and access the data in native FHIR format. The data formats like CSV, HLV2 can be transformed into FHIR using Google Cloud Data Fusion. The data can be further added to BigQuery for data analytics and exploration. Also, DICOM data can be interacted with using the API endpoint from Cloud Healthcare API. The HLV2 messages can be created and ingested using the MLLP adapter.
The Cloud Healthcare API is the conduit between the external sources, albeit a monolithic on-premises system or another cloud vendor. The API is compliant with HIPAA and also compliant with all global privacy standards.
Healthcare and clinical data exploration is a complex and scalable task. Google Cloud Platform provides the tools and services to ease the development and exploration of the data.
Read the success stories here:
Pluto7 helped a leading Healthcare Analytics Company in extracting entities with 90% accuracy
DxTerity: Using data-driven precision medicine to combat autoimmune disease
Click here to know more about Pluto7’s Healthcare ML or to get in touch to explore our healthcare solutions.
Reference and further read:
Link

